在 Day 11,我們第一次把 Popular Top-10 baseline 註冊進了 MLflow Model Registry。
今天,我們要邁進下一步:
而且我們會設計成 3 分鐘以內能跑完,確保體驗順暢。
請在 python-dev 容器中建立:
notebooks/day12_optuna_tuning.ipynb
這個 Notebook 將包含:
import os
import pandas as pd
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
ratings_test = pd.read_csv(os.path.join(DATA_DIR, "ratings_test.csv"))
print("Anime:", anime.shape)
print("Train:", ratings_train.shape)
print("Test:", ratings_test.shape)
import numpy as np
def precision_at_k(recommended, relevant, k=10):
return len(set(recommended[:k]) & set(relevant)) / k
這裡我們簡化:如果兩部動畫屬於同一個 genre,就算「相關」。
import mlflow
import optuna
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 抽樣 1000 筆,控制計算時間
anime_sample = anime.sample(1000, random_state=42).reset_index(drop=True)
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-optuna")
def objective(trial):
# 1️⃣ 抽樣參數
max_features = trial.suggest_int("max_features", 500, 1500)
ngram = trial.suggest_categorical("ngram_range", [(1,1), (1,2)])
min_df = trial.suggest_int("min_df", 1, 3)
# 2️⃣ 訓練 TF-IDF
vectorizer = TfidfVectorizer(
stop_words="english",
max_features=max_features,
ngram_range=ngram,
min_df=min_df
)
tfidf = vectorizer.fit_transform(anime_sample["genre"].fillna(""))
# 3️⃣ 相似度
sim_matrix = cosine_similarity(tfidf)
# 4️⃣ 隨機測試 50 部動畫
test_idx = np.random.choice(len(anime_sample), 50, replace=False)
scores = []
for idx in test_idx:
sim_scores = list(enumerate(sim_matrix[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
top_idx = [i for i, _ in sim_scores[1:11]]
recommended = anime_sample.iloc[top_idx]["name"].tolist()
relevant = anime_sample[anime_sample["genre"] == anime_sample.iloc[idx]["genre"]]["name"].tolist()
if len(relevant) > 1:
scores.append(precision_at_k(recommended, relevant, k=10))
avg_precision = np.mean(scores)
# 5️⃣ 記錄到 MLflow
with mlflow.start_run(nested=True):
mlflow.log_params({
"max_features": max_features,
"ngram_range": ngram,
"min_df": min_df
})
mlflow.log_metric("precision_at_10", avg_precision)
return avg_precision
# 只跑 10 trials,約 3 分鐘內完成
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=10)
print("最佳參數:", study.best_params)
把最佳參數重新訓練一個完整的模型(仍然用 1000 筆樣本,確保快),然後註冊進 Registry。
from mlflow import pyfunc
from mlflow.tracking import MlflowClient
best_params = study.best_params
vectorizer = TfidfVectorizer(
stop_words="english",
max_features=best_params["max_features"],
ngram_range=best_params["ngram_range"],
min_df=best_params["min_df"]
)
tfidf = vectorizer.fit_transform(anime_sample["genre"].fillna(""))
sim_matrix = cosine_similarity(tfidf)
class ItemBasedTFIDF(pyfunc.PythonModel):
def __init__(self, df, sim_matrix):
self.df = df
self.sim_matrix = sim_matrix
def predict(self, context, model_input):
anime_title = model_input[0]
idx = self.df[self.df["name"] == anime_title].index[0]
sim_scores = list(enumerate(self.sim_matrix[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
top_idx = [i for i, _ in sim_scores[1:11]]
return self.df.iloc[top_idx]["name"].tolist()
with mlflow.start_run(run_name="best-item-tfidf") as run:
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=ItemBasedTFIDF(anime_sample, sim_matrix),
registered_model_name="AnimeRecsysModel"
)
# 把最新版本升級到 Staging
client = MlflowClient()
latest = client.get_latest_versions("AnimeRecsysModel", stages=["None"])[-1]
client.transition_model_version_stage(
name="AnimeRecsysModel",
version=latest.version,
stage="Staging"
)
Notebook → Optuna 調參 (10 trials, ~3分鐘)
│
▼
MLflow Tracking (params + metrics)
│
▼
最佳模型 → Registry (AnimeRecsysModel v2, Staging)
今天我們在 Notebook 中完成了:
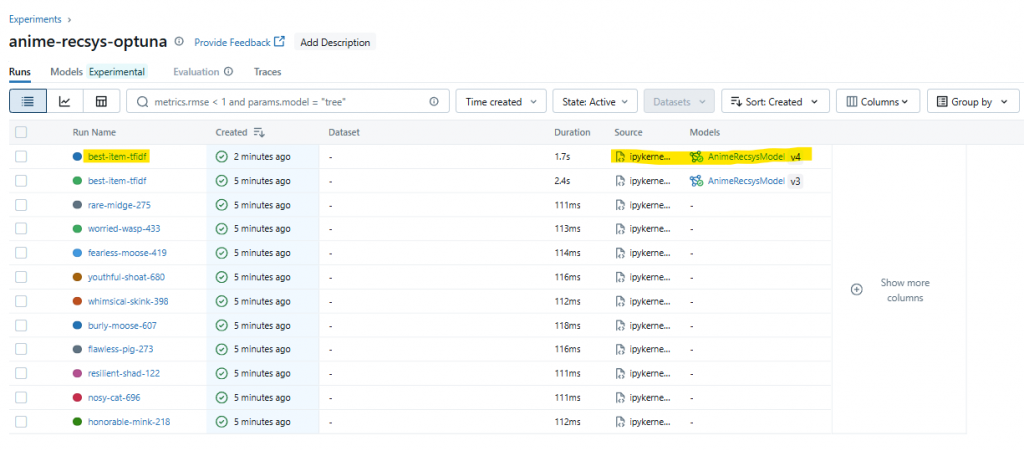
MLflow UI 現在應該可以看到:
AnimeRecsysModel v1:PopularTop10 baseline (Day 11)AnimeRecsysModel v2:Optuna 最佳 TF-IDF (Day 12)👉 下一步(Day 13),我們會把這些流程封裝成 Pipeline,讓實驗更有系統化。


 iThome鐵人賽
iThome鐵人賽